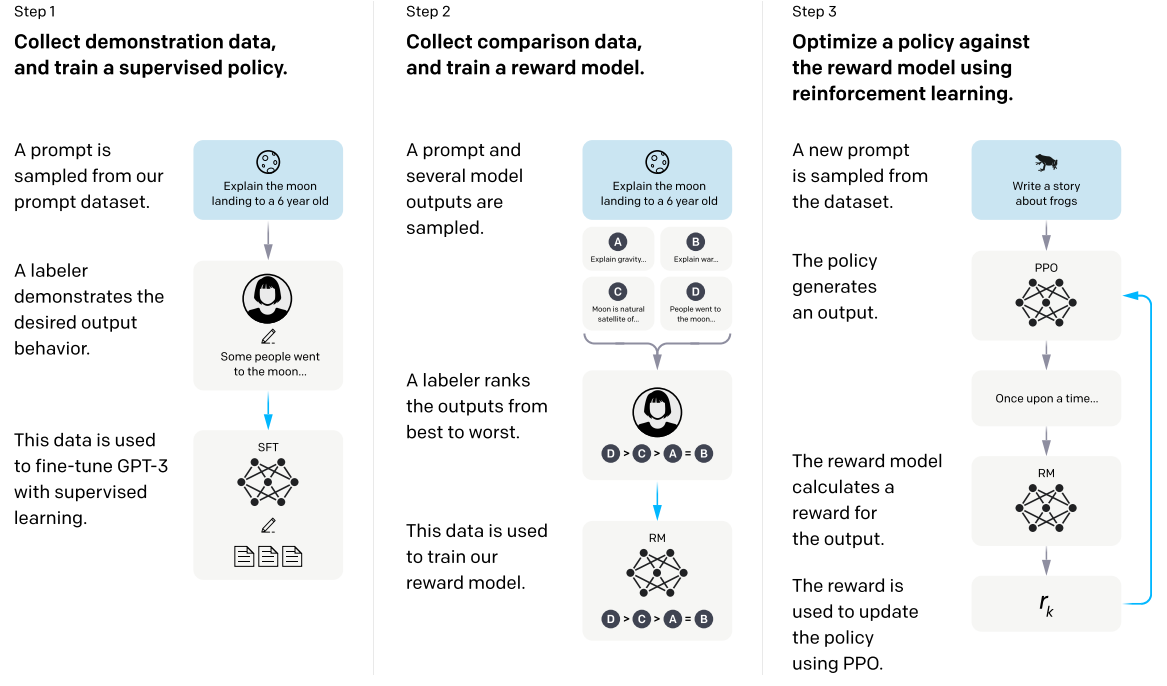
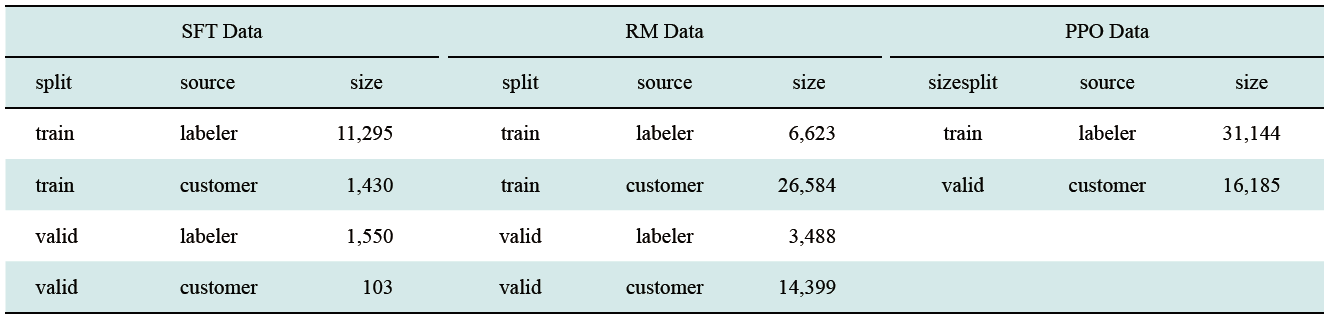
| [1] |
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. Advances in Neural Information Processing Systems 2017;5998-6008.
|
| [2] |
Ouyang L, Wu J, Jiang X, Almeida D, Wainwright CL, Mishkin P, et al. Training language models to follow instructions with human feedback. arXiv preprint arXiv 2022;2203.02155.
|
| [3] |
Bommasani R, Hudson DA, Adeli E, Altman R, Arora S, Arx SV, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv 2021;2108.07258.
|
| [4] |
Acosta JN, Falcone GJ, Rajpurkar P, Topol EJ. Multimodal biomedical AI. Nature Medicine 2022; 28:1773-1784.
doi: 10.1038/s41591-022-01981-2
pmid: 36109635
|
| [5] |
Dong L, Xu S, Xu B. Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2018;5884-5888.
|
| [6] |
Li N, Liu S, Liu Y, Zhao S, Liu M. Neural speech synthesis with transformer network. Proceedings of the AAAI Conference on Artificial Intelligence 2019; 33:6706-6713.
|
| [7] |
Vila LC, Escolano C, Fonollosa J AR, Costa-jussa MR. End-to-end speech translation with the transformer. IberSPEECH 2018;60-63.
|
| [8] |
Topal M O, Bas A, van Heerden I. Exploring transformers in natural language generation: Gpt, bert, and xlnet. arXiv preprint arXiv 2021;2102.08036.
|
| [9] |
Gao X, Qian Y, Gao A. COVID-VIT: classification of COVID-19 from CT chest images based on vision transformer models. arXiv preprint arXiv 2021;2107.01682.
|
| [10] |
Costa G S S, Paiva A C, Junior G B, Ferreira MM. COVID-19 automatic diagnosis with CT images using the novel transformer architecture. Anais Do XXI Simpósio Brasileiro De Computação Aplicada À Saúde 2021:293-301.
|
| [11] |
Zhang Z, Sun B, Zhang W. Pyramid medical transformer for medical image segmentation. arXiv preprint arXiv 2021;2104.14702.
|
| [12] |
Manning C D. Human language understanding & reasoning. Daedalus 2022; 151:127-138.
doi: 10.1162/daed_a_01905
|
| [13] |
Radford A, Narasimhan K, Salimans T, Sutskever I. Improving language understanding by generative pre-training. OpenAI Blog 2018.
|
| [14] |
Radford A, Wu J, Child R, Luan D, Amodei D, Sutskever I. Language models are unsupervised multitask learners. OpenAI Blog 2019.
|
| [15] |
Larochelle H, Erhan D, Bengio Y. Zero-data learning of new tasks. AAAI 2008; 1:646-651.
|
| [16] |
Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P. Language models are few-shot learners. Advances in Neural Information Processing Systems 2020; 33:1877-1901.
|
| [17] |
Patel S B, Lam K. ChatGPT: the future of discharge summaries? The Lancet Digital Health 2023; 5:e107-e108.
doi: 10.1016/S2589-7500(23)00021-3
|
| [18] |
Rae JW, Borgeaud S, Cai T, Millican K, Hoffmann J, Song F, et al. Scaling language models: methods, analysis & insights from training gopher. arXiv preprint arXiv 2021;2112.11446.
|
| [19] |
Nye M, Andreassen AJ, Gur-Ari G, Michalewski H, Austin J, Bieber D, et al. Show your work: scratchpads for intermediate computation with language models. arXiv preprint arXiv 2021;2112.00114.
|
| [20] |
Kojima T, Gu SS, Reid M, Matsuo Y, Iwasawa Y. Large language models are zero-shot reasoners. arXiv preprint arXiv 2022;2205.11916.
|
| [21] |
Christiano P F, Leike J, Brown T, Martic M, Legg S, Amodei D. Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems 2017;4302-4310.
|
| [22] |
Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms. arXiv preprint arXiv 2017;1707.06347.
|
| [23] |
Wei J, Bosma M, Zhao VY, Guu K, Yu AW, Lester B, et al. Finetuned language models are zero-shot learners. arXiv preprint arXiv 2021;2109.01652.
|
| [24] |
Zhang Z, Zhang A, Li M, Smola A. Automatic chain of thought prompting in large language models. arXiv preprint arXiv 2022;2210.03493.
|
| [25] |
25Vemprala S, Bonatti R, Bucker A, Kapoor A. ChatGPT for robotics: design principles and model abilities. Microsoft 2023.
|
| [26] |
OpenAI. GPT-4 technical report. arXiv preprint arXiv 2023;2303.08774.
|
| [27] |
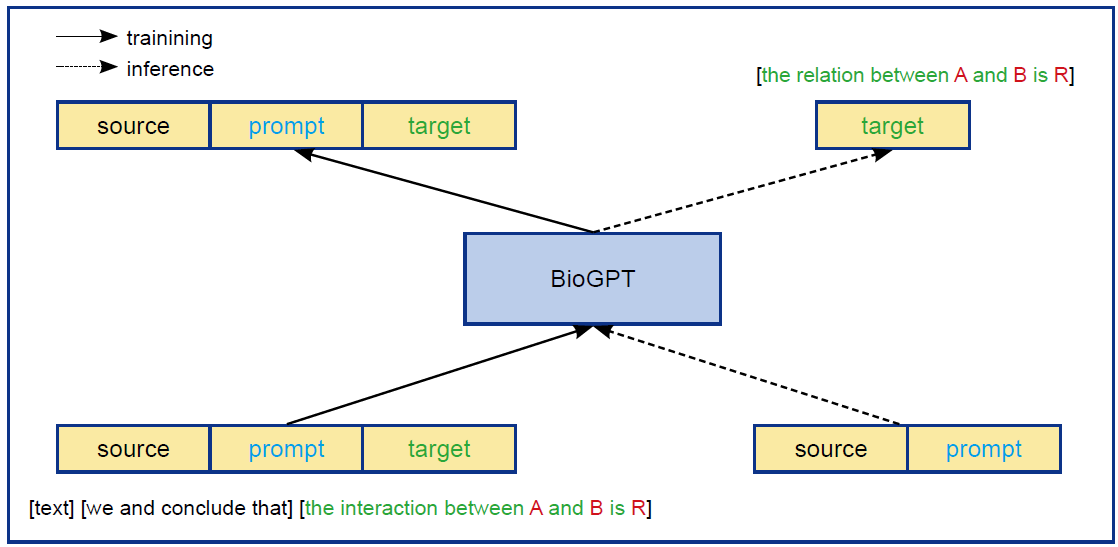
Luo RQ, Sun LA, Xia YC, Qin T, Zhang S, Poon H, et al. BioGPT: generative pre-trained transformer for biomedical text generation and mining. arXiv preprint arXiv 2023;2210.10341.
|
| [28] |
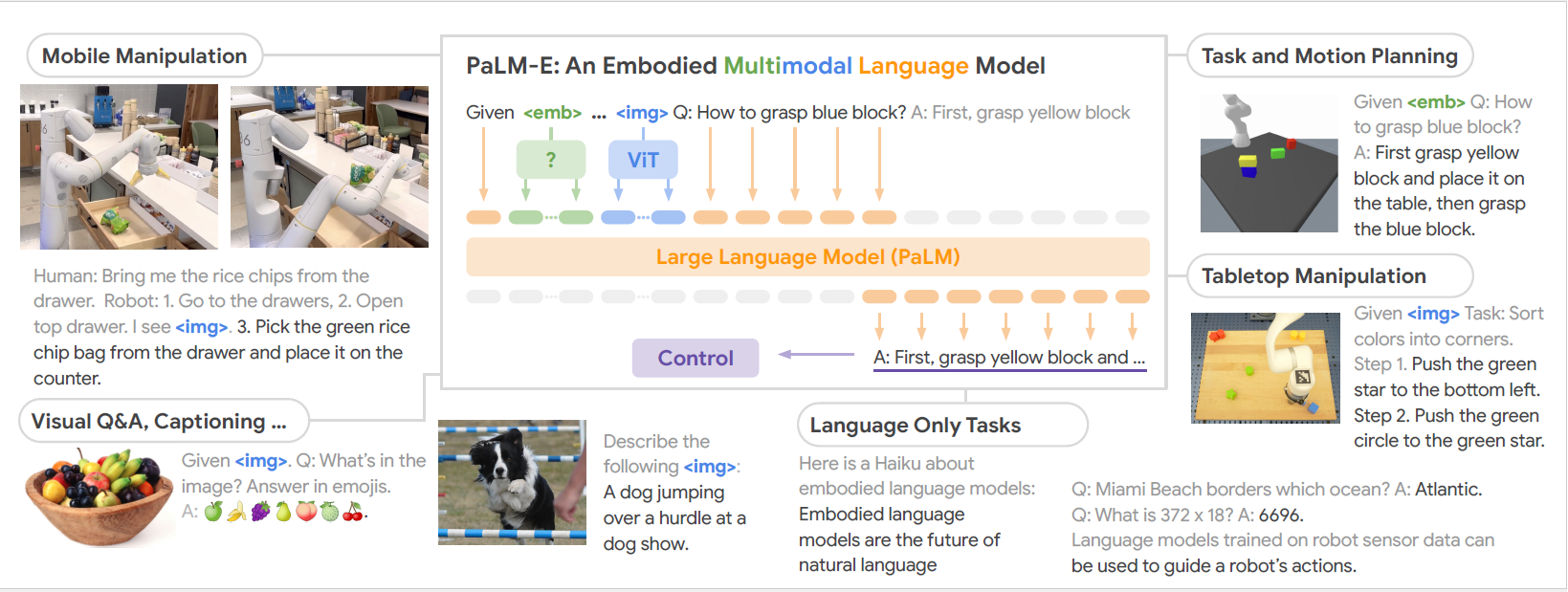
Driess D, Xia F, Sajjadi MSM, Lynch C, Chowdhery A, Ichter B, et al. PaLM-E: an embodied multimodal language model. arXiv preprint arXiv 2023;2303.03378.
|
| [29] |
Korngiebel D M, Mooney S D. Considering the possibilities and pitfalls of Generative Pre-trained Transformer 3 (GPT-3) in healthcare delivery. NPJ Digital Medicine 2021; 4:93.
doi: 10.1038/s41746-021-00464-x
pmid: 34083689
|
| [30] |
Kung TH, Cheatham M, Medenilla A, Sillos C, Leon LD, Elepaño C, et al. Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models. PLOS Digital Health 2023; 2:e0000198.
doi: 10.1371/journal.pdig.0000198
|
| [31] |
Agbavor F, Liang H. Predicting dementia from spontaneous speech using large language models. PLOS Digital Health 2022; 1: e0000168.
doi: 10.1371/journal.pdig.0000168
|
| [32] |
Wang S, Zhao Z, Ouyang X, Wang Q, Shen DG. ChatCAD: interactive computer-aided diagnosis on medical image using large language models. arXiv preprint arXiv 2023;2302.07257.
|
 ), Linxue Qian, MDb
), Linxue Qian, MDb
 Advanced Ultrasound in Diagnosis and Therapy (AUDT)
is licensed under a Creative Commons Attribution 4.0 International License.
Advanced Ultrasound in Diagnosis and Therapy (AUDT)
is licensed under a Creative Commons Attribution 4.0 International License.