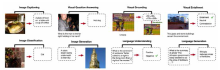
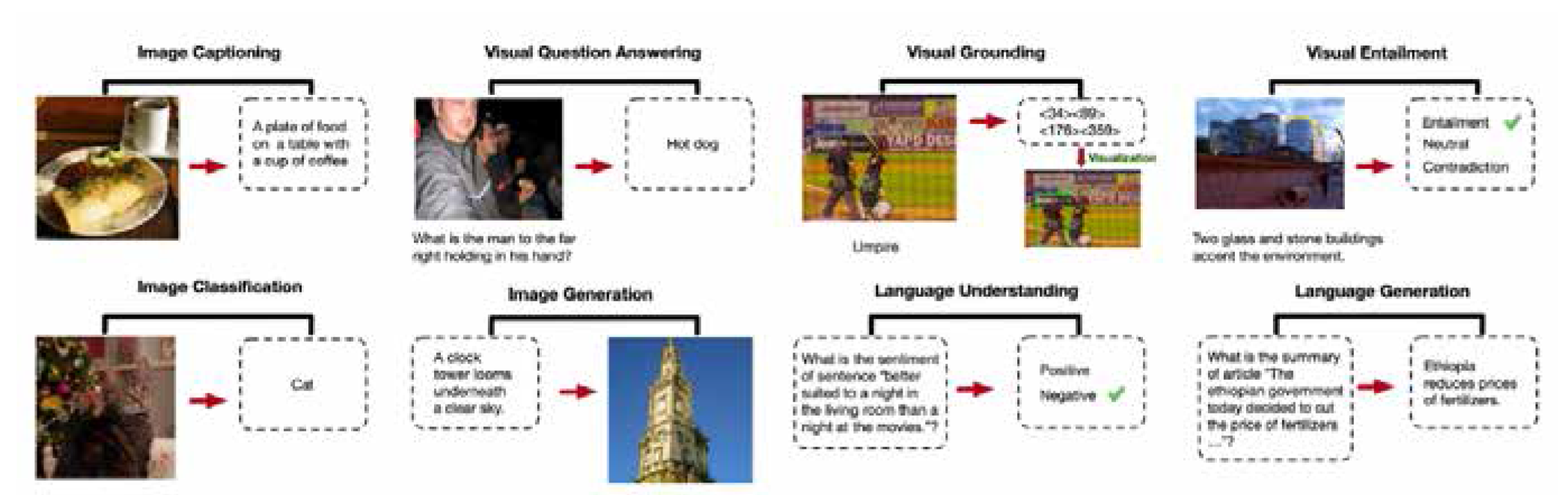
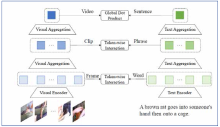
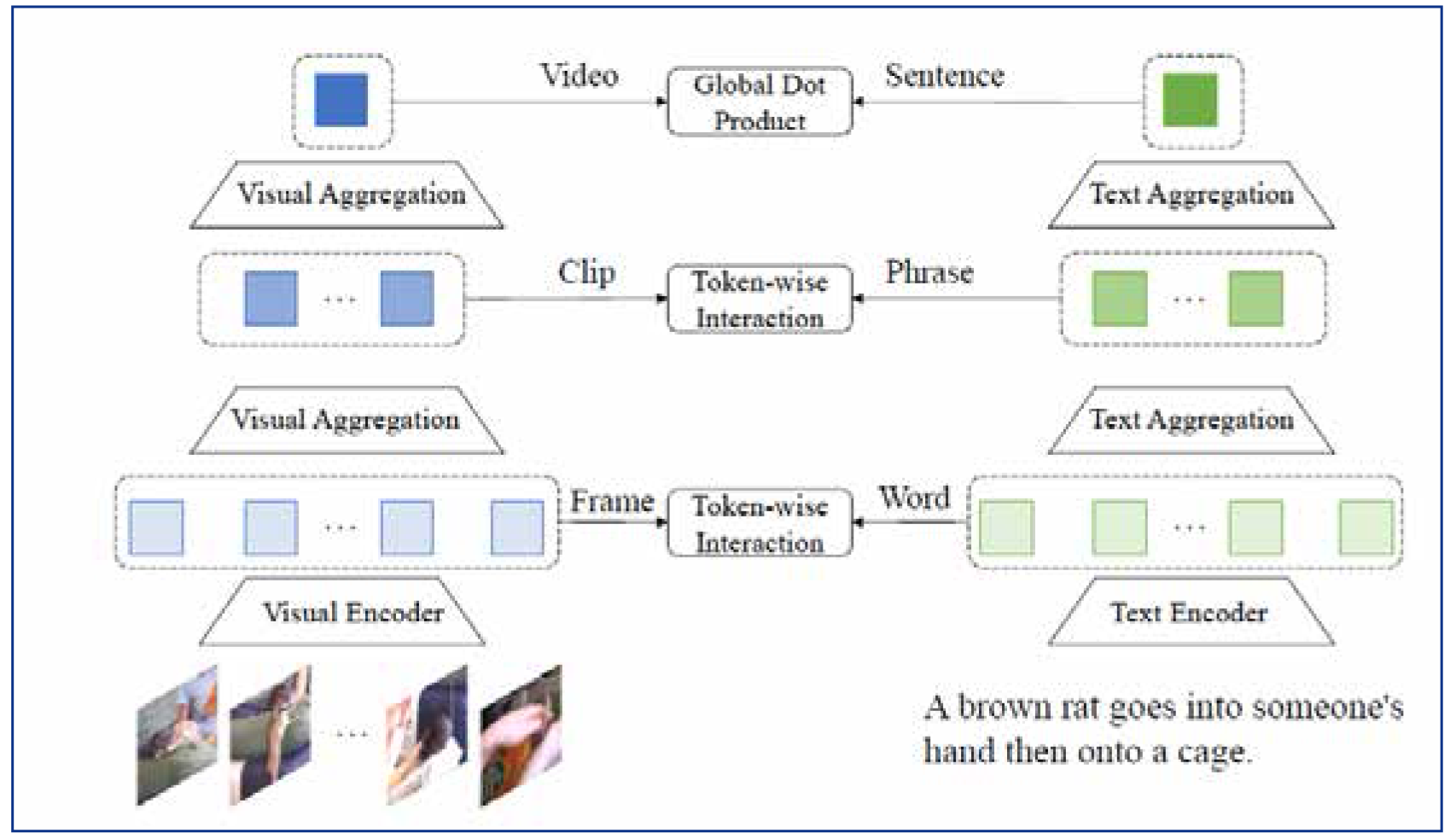
| [1] |
OpenAI. GPT-4 technical report. arXiv preprint arXiv 2023; 2303.08774.
|
| [2] |
Bengio Y. Deep learning of representations for unsupervised and transfer learning. Proceedings of ICML workshop on unsupervised and transfer learning. JMLR Workshop and Conference Proceedings 2012;17-36.
|
| [3] |
Wei J, Tay Y, Bommasani R, Raffel C, Zoph B, Borgeaud S, et al. Emergent abilities of large language models. arXiv preprint arXiv 2022; 2206.07682.
|
| [4] |
Brown T, Mann B, Ryder N, Subbiah M, Kaplan D, Dhariwal P, et al. Language models are few-shot learners. Advances in neural information processing systems 2020; 33:1877-1901.
|
| [5] |
Thoppilan R, De Freitas D, Hall J, Shazeer N, Kulshreshtha A, Cheng H, et al. Lamda: language models for dialog applications. arXiv preprint arXiv 2022;2201.08239.
|
| [6] |
Devlin J, Chang M W, Lee K, Toutanova K. Bert: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv 2018;1810.04805.
|
| [7] |
Radford A, Narasimhan K, Salimans T, Sutskever I. Improving language understanding by generative pre-training. OpenAI 2018.
|
| [8] |
Qiu X, Sun T, Xu Y, Shao Y, Dai N, Huang X. Pre-trained models for natural language processing: a survey. Science China Technological Sciences 2020; 63:1872-1897.
doi: 10.1007/s11431-020-1647-3
|
| [9] |
Xu HH, Zhang XP, Li H, Xie LX, Dai WR, Xiong HK, et al. Seed the views: hierarchical semantic alignment for contrastive representation learning. IEEE Transactions on Pattern Analysis and Machine Intelligence 2022; 45:3753-3767.
|
| [10] |
He K, Fan H, Wu Y, Xie S, Girshick R. Momentum contrast for unsupervised visual representation learning. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2020;9729-9738.
|
| [11] |
Bao F, Nie S, Xue K, Li C, Pu S, Wang Y, et al. One transformer fits all distributions in multi-modal diffusion at scale. arXiv preprint arXiv 2023;2303.06555.
|
| [12] |
Sun Y, Wang S, Li Y, Feng S, Chen X, Zhang H, et al. Ernie: enhanced representation through knowledge integration. arXiv preprint arXiv 2019;1904.09223.
|
| [13] |
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A, et al. Attention is all you need. Advances in neural information processing systems 2017;30.
|
| [14] |
Sun Y, Wang S, Li Y, Feng S, Tian H, Wu H, et al. Ernie 2.0: a continual pre-training framework for language understanding. Proceedings of the AAAI conference on artificial intelligence 2020; 34:8968-8975.
doi: 10.1609/aaai.v34i05.6428
|
| [15] |
Yang Z, Dai Z, Yang Y, Carbonell J, Salakhutdinov R, Le Q. Xlnet: generalized autoregressive pretraining for language understanding. Advances in neural information processing systems 2019;32.
|
| [16] |
Zhang Y, Yang Q. A survey on multitask learning. arXiv preprint arXiv 2017;1707.08114.
|
| [17] |
Sun Y, Wang S, Feng S, Ding S, Pang C, Shang J, et al. Ernie 3.0: large-scale knowledge enhanced pre-training for language understanding and generation. arXiv preprint arXiv 2021;2107.02137.
|
| [18] |
Liu X, He P, Chen W, Gao J. Multi-task deep neural networks for natural language understanding. arXiv preprint arXiv 2019;1901.11504.
|
| [19] |
Xi T, Sun Y, Yu D, Li B, Peng N, Zhang G, et al. UFO: unified feature optimization. arXiv preprint arXiv 2022;2207.10341.
|
| [20] |
Li Y, Qian Y, Yu Y, Qin X, Zhang C, Liu Y, et al. Structext: structured text understanding with multi-modal transformer. Proceedings of the 29th ACM International Conference on Multimedia 2021;1912-1920.
|
| [21] |
Chen X, Ding M, Wang X, Xin Y, Mo S, Wang Y, et al. Context autoencoder for self-supervised representation learning. arXiv preprint arXiv 2022;2202.03026.
|
| [22] |
Feng Z, Zhang Z, Yu X, Fang Y, Li L, Chen X, et al. ERNIE-ViLG 2.0: improving text-to-image diffusion model with knowledge-enhanced mixture-of-denoising-experts. arXiv preprint arXiv 2022;2210.15257.
|
| [23] |
Peng Q, Pan Y, Wang W, Luo B, Zhang Z, Huang Z, et al. ERNIE-Layout: layout knowledge enhanced pre-training for visually-rich document understanding. arXiv preprint arXiv 2022;2210.06155.
|
| [24] |
Ouyang L, Wu J, Jiang X, Almeida D, Wainwright C, Mishkin P, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 2022; 35:27730-27744.
|
| [25] |
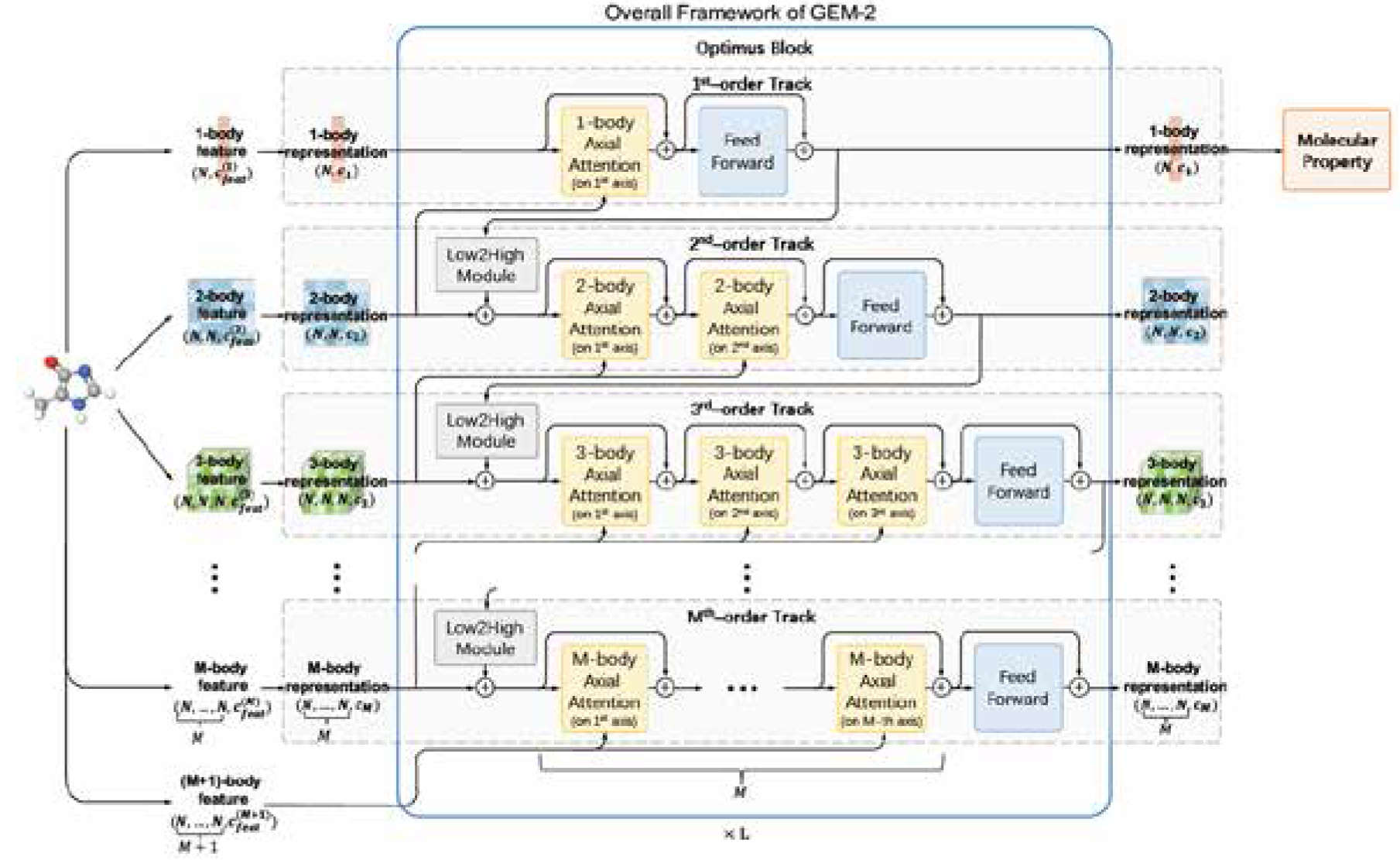
Liu L, He D, Fang X, Zhang S, Wang F, He J, et al. GEM-2: next generation molecular property prediction network by modeling full-range many-body interactions. arXiv preprint arXiv 2022;2208.05863.
|
| [26] |
Wang G, Fang X, Wu Z, Liu Y, Xue Y, Xiang Y, et al. Helixfold: An efficient implementation of alphafold2 using paddlepaddle. arXiv preprint arXiv 2022;2207.05477.
|
| [27] |
Fang X, Wang F, Liu L, He J, Lin D, Xiang Y, et al. Helixfold-single: msa-free protein structure prediction by using protein language model as an alternative. arXiv preprint arXiv 2207;13921,2022.
|
| [28] |
Wang W, Bi B, Yan M, Wu C, Bao Z, Xia J, et al. Structbert: Incorporating language structures into pre-training for deep language understanding. arXiv preprint arXiv 2019;1908.04577.
|
| [29] |
Luo F, Wang W, Liu J, Liu Y, Bi B, Huang S, et al. VECO: variable and flexible cross-lingual pre-training for language understanding and generation. arXiv preprint arXiv 2020;2010.16046.
|
| [30] |
Bi B, Li C, Wu C, Yan M, Wang W, Huang S, et al. Palm: pre-training an utoencoding&autoregressive language model for context-conditioned generation. arXiv preprint arXiv 2020;2004.07159.
|
| [31] |
Li C, Bi B, Yan M, Wang W, Huang S, Huang F, et al. Structurallm: structural pre-training for form understanding. arXiv preprint arXiv 2021;2105.11210.
|
| [32] |
Xu Y, Li M, Cui L, Huang S, Wei F, Zhou M. Layoutlm: pre-training of text and layout for document image understanding. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining 2020;1192-1200.
|
| [33] |
Jaume G, Ekenel H K, Thiran J P. Funsd: a dataset for form understanding in noisy scanned documents. 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW) 2019; 2:1-6.
|
| [34] |
Wang P, Yang A, Men R, Lin J, Bai S, Li Z, et al. Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. arXiv preprint arXiv 2022;2202.03052.
|
| [35] |
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition 2016;770-778.
|
| [36] |
Jacobs RA, Jordan MI, Nowlan SJ, Hinton GE. Adaptive mixtures of local experts. Neural computation 1991; 3:79-87.
doi: 10.1162/neco.1991.3.1.79
pmid: 31141872
|
| [37] |
Shazeer, Noam, Mirhoseini A, Maziarz K, Davis A, Le Q, Hinton G, et al. Outrageously large neural networks: the sparsely-gated mixture-of-experts layer. arXiv preprint arXiv 2017;1701.06538.
|
| [38] |
Bengio Y, Louradour J, Collobert R, Weston J. Curriculum learning. Proceedings of the 26th annual international conference on machine learning 2009; 41-48.
|
| [39] |
Jiang J, Min S, Kong W, Gong D, Wang H, Li Z, et al. Hunyuan_tvr for text-video retrivial. arXiv preprint arXiv 2022;2204.0338.
|
| [40] |
Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. International conference on machine learning 2021;8748-8763.
|
| [41] |
Zeng W, Ren X, Su T, Wang H, Liao Y, Wang Z, et al. PanGu-α: large-scale autoregressive pretrained chinese language models with auto-parallel computation. arXiv preprint arXiv 2021;2104.12369.
|
| [42] |
Zhang L, Chen Q, Chen Z, Han Y, Li Z, Cao Z. Replacement as a self-supervision for fine-grained vision-language pre-training. arXiv preprint arXiv 2023;2303.05313.
|
| [43] |
Wang W, Dai J, Chen Z, Huang Z, Li Z, Zhu X, et al. Internimage: Exploring large-scale vision foundation models with deformable convolutions. arXiv preprint arXiv 2022;2211.05778.
|
| [44] |
Zhu X, Zhu J, Li H, Wu X, Li H, Wang X, et al. Uni-perceiver: Pre-training unified architecture for generic perception for zero-shot and few-shot tasks. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022;16804-16815.
|
| [45] |
Cui Y, Che W, Liu T, Qin B, Yang Z. Pre-training with whole word masking for chinese bert. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021; 29:3504-3514.
doi: 10.1109/TASLP.2021.3124365
|
| [46] |
Wang S, Zhao Z, Ouyang X, Wang Q, Shen D. ChatCAD: interactive computer-aided diagnosis on medical image using large language models. arXiv preprint arXiv 2023;2302.07257.
|
| [47] |
Tschandl P, Rinner C, Apalla Z, Argenziano G, Codella N, Halpern A, et al. Human-computer collaboration for skin cancer recognition. Nature Medicine 2020; 26:1229-1234.
doi: 10.1038/s41591-020-0942-0
pmid: 32572267
|
 ), Xing Yu, MDb
), Xing Yu, MDb
 Advanced Ultrasound in Diagnosis and Therapy (AUDT)
is licensed under a Creative Commons Attribution 4.0 International License.
Advanced Ultrasound in Diagnosis and Therapy (AUDT)
is licensed under a Creative Commons Attribution 4.0 International License.